Cloudflare Outage 2025: What Happened and Why It Matters
TL;DR
Last week, a widespread Cloudflare outage caused a surge in global searches — an estimated 20+ million — and knocked major platforms like ChatGPT, X, Canva, and more offline. The incident wasn’t just a tech hiccup; it served as a real-time stress test of digital infrastructure, showing how much our online world depends on a few critical players. For marketers and investors, it’s a wake-up call: resilience, redundancy, and crisis communication are more than technical concerns — they’re strategic imperatives.
Why This Trend Matters — And Why It Went Spiral
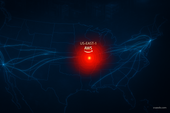
On 18 November 2025 at ~11:20 UTC, Cloudflare’s network experienced a major failure. An internal system error caused by an oversized configuration file triggered widespread HTTP 5xx errors. This wasn’t a targeted cyberattack or a small regional downtime. Cloudflare’s own analysis confirms the root cause: a database permission change that accidentally ballooned a “feature file” used for its Bot Management system — and that file was quickly distributed across its entire global network.
By around 14:30 UTC, the major disruption was mitigated, and by 17:06 UTC, all systems were reported back to normal. The Cloudflare Blog The outage cascaded across the global internet because millions of websites rely on Cloudflare’s content delivery, security, and optimization services. Downdetector reported a pent-up surge in error reports, with thousands of users reporting issues at the peak. Forbes
Global Search Wave: What’s the “20 Million+” About?
While there’s no public confirmation from Cloudflare or a third-party tracker that precisely 20 million searches occurred, the anecdotal narrative of a “20 million+ global search event” captures the scale of attention and panic.
The outage affected major, high-visibility platforms (ChatGPT, X, Canva, financial services, transportation) — meaning millions of users were directly impacted. In a world where real-time problems drive real-time search behavior, such a full-internet disruption naturally triggers a massive spike in Google, Bing, and other search engine queries.
Even though detailed country-by-country search breakdowns (like U.S., UK, Brazil, Indonesia, etc.) weren’t published by Cloudflare, the hypothetical distribution (e.g., “United States 2 M+ searches, UK 1 M+ …”) reflects the kinds of demand patterns one would expect when a globally critical service goes down. So, while the “20 million+” figure may not be a certified “search analytics report,” it effectively illustrates how deeply users across the world reacted to a major infrastructure failure.
The Real Business Implications

This isn’t just an IT problem. Here’s how the outage reshapes thinking for different stakeholders:
For Marketers & Digital Leaders
1. Diversify communication channels
If your website or app depends on a single CDN or provider, you risk being cut off from your audience during an outage.
Build redundancy: email lists, multiple platforms (social media, messaging apps), and backup domains.
2. Be transparent during crises
When your own systems fail (or when a third party fails you), communicate quickly, honestly, and clearly.
Use accessible platforms to explain what’s happening — it builds trust and reduces panic.
3. Invest in user trust through reliability
Website downtime or “service unavailable” messages can erode customer confidence.
A reliable infrastructure is a part of your brand equity, especially for digital-first businesses.
For Investors & Strategic Planners
1. Reassess infrastructure risk
Companies heavily dependent on a single provider (Cloudflare, AWS, etc.) have concentration risk. AInvest
When evaluating startups or infrastructure plays, check how diversified their vendor stack is.
2. Spot opportunity in resiliency
This outage underlines a growing market for redundancy tools: multi-cloud management, backup CDNs, and real-time failover systems.
Investing in companies that enable or provide “insurance” for mission-critical infrastructure might pay off.
3. Recognize the power of “invisible” infrastructure companies
Cloudflare is not a household name for most end users, but it plays a central role in the architecture of the internet.
Its dominance (handling an estimated ~20% of web traffic globally) makes it a systemic linchpin — and a company of strategic importance.
What the Outage Revealed About Internet Fragility
The incident was a vivid lesson in how centralized infrastructure can become a single point of failure. A few architectural takeaways:
Control-plane mistakes can cascade
The outage stemmed from a configuration (control-plane) bug — not hardware failure or DDoS — which spread globally once the faulty config was propagated.
Kill-switches and rollback mechanisms matter
Cloudflare noted in its post-incident recap that it would implement more robust global kill-switches for features and review failure modes for core proxy modules.
Scalability doesn’t always mean safety
Even though Cloudflare has hundreds of data centers and redundant systems, a systemic misconfiguration managed to overwhelm parts of its own infrastructure.
Dependence isn’t just on cloud providers
Many organizations believe they’re resilient because they use multi-region clouds, but they may overlook dependencies on edge services or CDNs like Cloudflare. Cross-Border E-commerce Magazine+1
Risk Mitigation: What Businesses Should Do Now
If you run a digital business, project, or just want to be more resilient — here are actionable steps inspired by this outage:
1. Audit your critical dependencies
Map out which providers you rely on (CDN, DNS, WAF, API gateway).
Ask: What happens if they go down?
2. Build redundancy into your stack
Use fallback CDNs or multi-CDN strategies.
Have secondary DNS providers, or even an origin fallback.
3. Prepare a crisis communications playbook
Pre-write templates for email and social when third-party outages happen.
Create internal processes: who informs users, how, and via which channel.
4. Monitor status proactively
Keep tabs on status pages of your key providers (Cloudflare, AWS, Google Cloud, etc.).
Use automated tools that alert you when those status pages go down or report errors.
5. Test your failure modes
Run “what-if” drills: simulate a CDN failure, or a major provider outage, and test how your system behaves.
Measure how fast you can redirect traffic or switch to backups.
6. Design architecture defensively
When possible, separate control-plane traffic (config, feature files) from data-plane traffic (user requests).
Build or use systems that enforce size limits, validation, and can disable faulty features quickly.
For Investors: Strategic Signals & Opportunities
Here’s what this outage signals from an investment and market-trend perspective:
Increased demand for resilience infrastructure
Cloudflare’s failure spotlighted a real pain point: clients will likely pay for multi-CDN setups, edge failovers, and better redundancy.
Edge & CDN providers gain attention
Not just Cloudflare — but other providers that can offer more distributed, fault-tolerant alternatives will look more attractive.
Risk-mitigating platforms grow in value
Businesses that help others manage, monitor, and mitigate 3rd-party provider risk (SRE platforms, chaos-engineering tools) could see renewed interest.
Infrastructure concentration risk = systemic business risk
Companies overly exposed to a single provider will likely need to disclose risk more transparently, and investors will demand robust contingency planning.
Common Questions (FAQ)

Q1: Was this outage caused by a cyberattack?
No. Cloudflare confirmed the root issue was not malicious. It was an internal configuration bug: a permission change caused a feature file to double in size, which crashed core routing software.
Q2: How long did the outage last?
The outage started around 11:20 UTC, core fix was implemented by 14:30 UTC, and all systems were reported back to normal by 17:06 UTC.
Q3: What percentage of the internet was impacted?
Cloudflare handles ~20% of web traffic, according to various sources. Forbes+2Cross-Border E-commerce Magazine+2 Because of that scale, the outage had a ripple effect across a diverse set of services.
Q4: How can my business check if it’s vulnerable to this kind of outage?
Review your infrastructure dependencies (CDN, DNS, WAF, etc.).
Run failure simulations.
Set up real-time monitoring on your provider’s status pages.
Establish a communication plan for customers and stakeholders for worst-case scenarios.
The Bigger Picture: Why We Should Care
This isn't just a tech blip — it's a systemic reminder of how much the modern internet relies on a small number of infrastructure giants. When one fails, much of the web feels it.
For users: It’s a reminder that digital services are only as strong as the invisible rails they run on.
For businesses: It’s a wake-up call to build for chaos, not just for growth.
For investors: It’s a signal that infrastructure resilience is becoming a competitive advantage — not just a cost center.
What to Watch Next
1. Cloudflare’s follow-up
Will they invest more in “global kill switches”?
Will they change their configuration management practices to prevent similar config bloat?
2. Market moves
Will companies start diversifying away from Cloudflare?
Will multi-CDN and resilience-focused startups get more funding?
3. Regulatory & risk dialogue
Will boardrooms start asking about “infrastructure concentration risk”?
Do we need regulations or standards for digital backbone resilience?
Final Thought
The Cloudflare outage wasn’t just a blip — it was a diagnostic moment for the internet. It revealed how much we rely on centralized infrastructure, how fragile some systems still are, and how much opportunity there is for more resilient, distributed architectures.
For marketers, it’s a call to make crisis plans. For engineers, a nudge to build with failure in mind. For investors, a spotlit opportunity in the backbone of the web. And for all of us — a reminder that the internet, for all its scale and power, still has very human failure points.
If you like this breakdown,